Two Papers
Robustness and Security in ML Systems, Spring 2021
January 19, 2021
Yann LeCun
Chief AI Scientist (and several other titles) at Facebook, “founding father of convolutional nets.”
The Problem
How to turn handwritten ZIP codes from envelopes into numbers


Network Input

Input: 16x16 grid of greyscale values, from -1 to 1
Normalized from ~40x60px original, preserving aspect ratio. Network needs consistent size!
Convolution
A convolution is used to “see” patterns around a pixel like horizontal, vertical or diagonal edges.

It’s just linear algebra: a kernel is applied to create a new version of a pixel dependent on the pixels around it. The kernel (or convolutional matrix) is just a matrix that is multiplied against each pixel and its surroundings.
Application of the convolution
Edges of the image are padded with -1 to allow kernel to be applied to outermost pixels. The result is called a feature map.
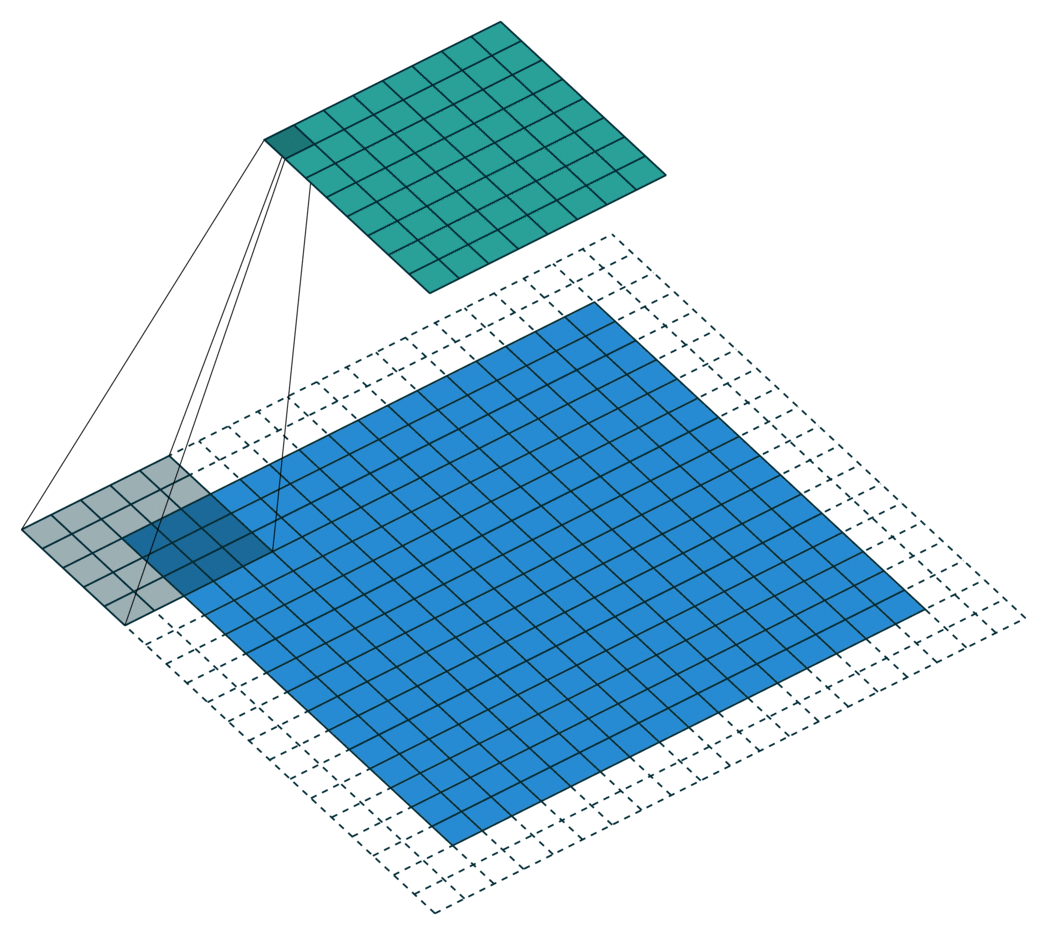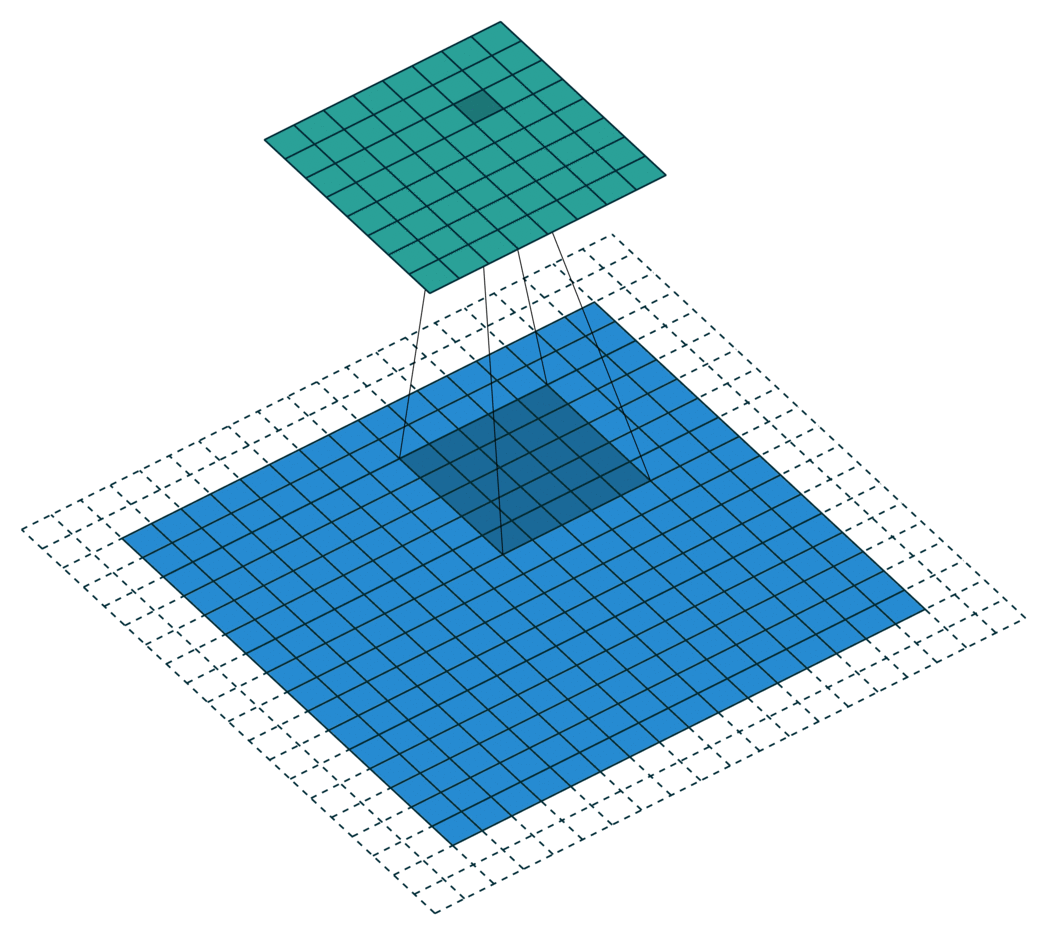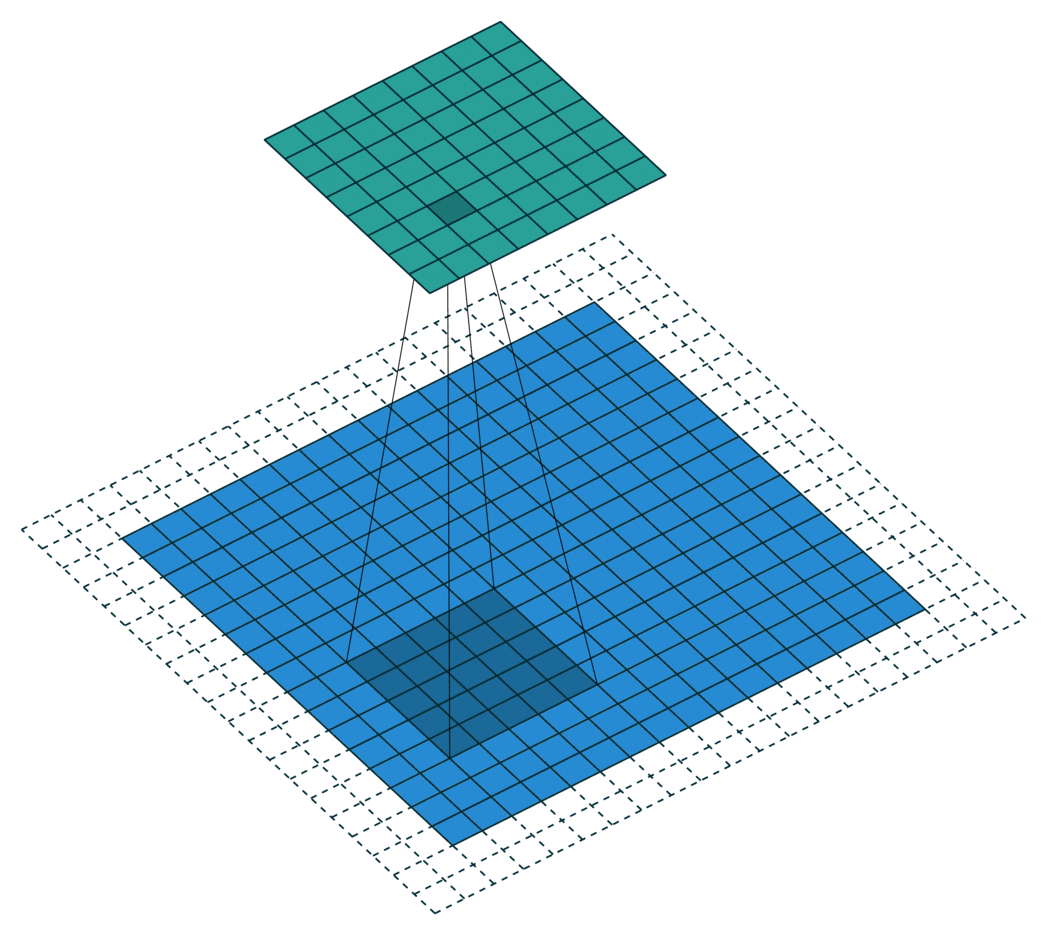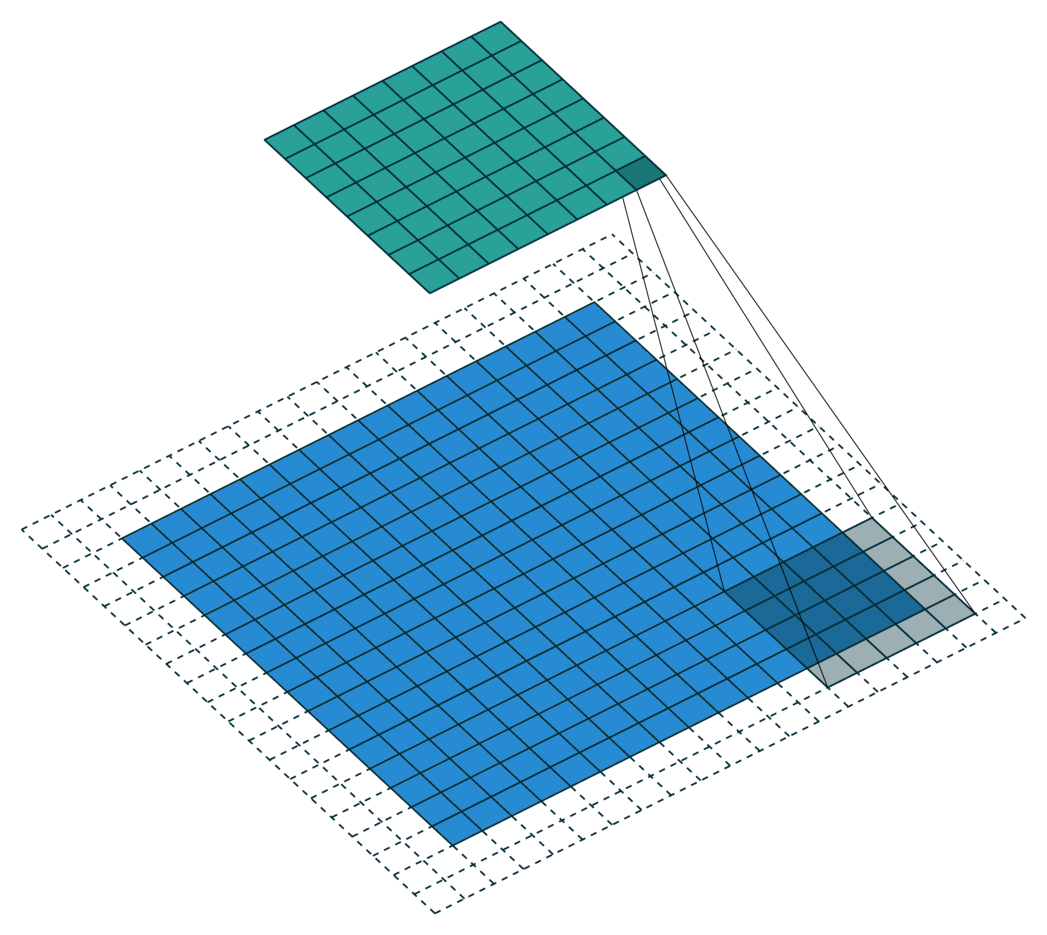
A single kernel map
The -1 +1 range of each feature map highlights a specific type of feature at a specific location.
Layer: H1
Four different 5x5 kernels are applied, creating four different 576-node feature maps that each highlight a different type of feature.

Layer: H2
We don’t need all that detail, though! Layer H2 averages the 24x24 feature maps down to 12x12, converting local sets of 4 nodes in H1 to a single node in H2.

Layer: H3
H3 is another feature layer, operating just like H1 but with 12 8x8 feature maps. Each kernel is again 5x5.

H2-H3 connections
Note that not all H3 kernels are applied to all H2 layers. Selection is “guided by prior knowledge of shape recognition.” This simplifies the network.

Layer: H4
H4 is similar to H2, in that it averages the previous layer. This reduces H3’s 8x8 size to 4x4.
Output
10 nodes, fully connected to H4. Each activates between -1 and +1 with a higher score meaning a more likely prediction for that digit.

Performance

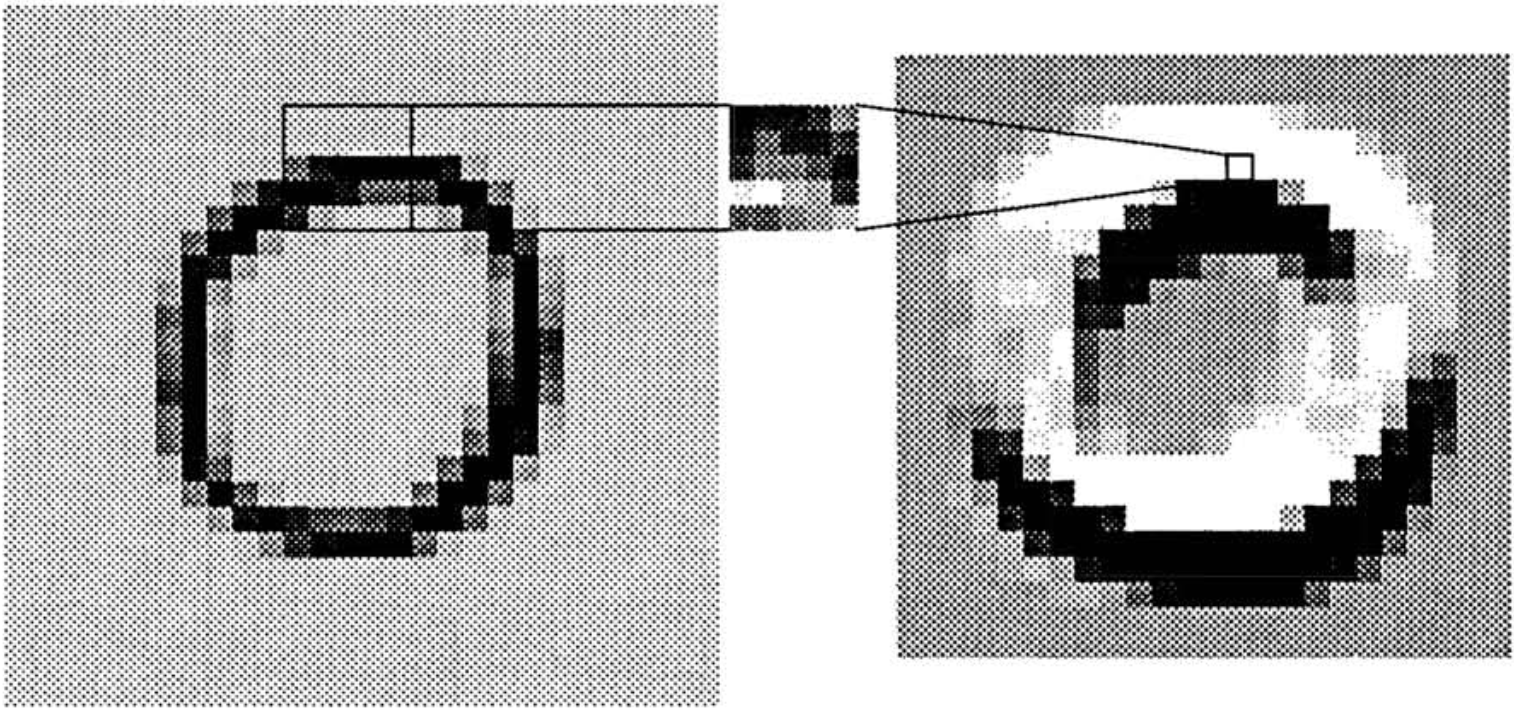
Robust model that generalizes very well when presented with unusual representations of digits.
Throughput is mainly limited by the normalization step! Reaches 10-12 classifications per second.