%pip install --upgrade --quiet olmocr openaiRunning olmocr on macOS with LM Studio
olmocr is a magic new piece of software that does a beautiful perfect wonderful OCR. In their own words:
olmOCR is an open-source tool designed for high-throughput conversion of PDFs and other documents into plain text while preserving natural reading order. It supports tables, equations, handwriting, and more.
Unfortunately the Python package requires a fancy GPU. But let’s see how we can run it with normal boring macOS!
LM Studio
We’re going to use LM Studio to run our inference server because I find it very easy and I’m very lazy. Go download it.
Getting the model
First, you’ll need to download the model by opening LM Studio, searching for olmocr gguf, and downloading whatever size model fits on your machine.
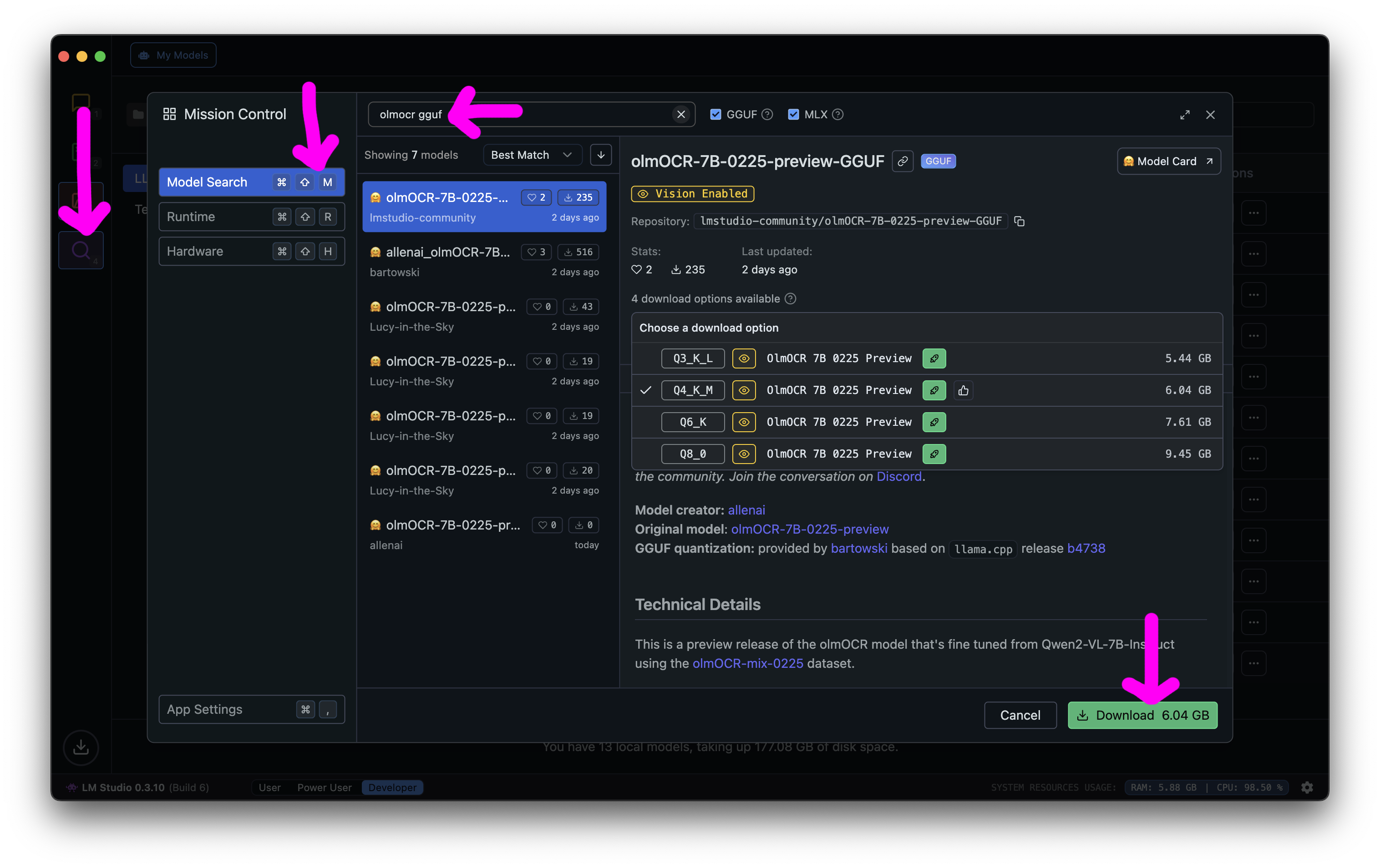
Then you’ll need to start the server by going to the Developer area and clicking the little start server slider.
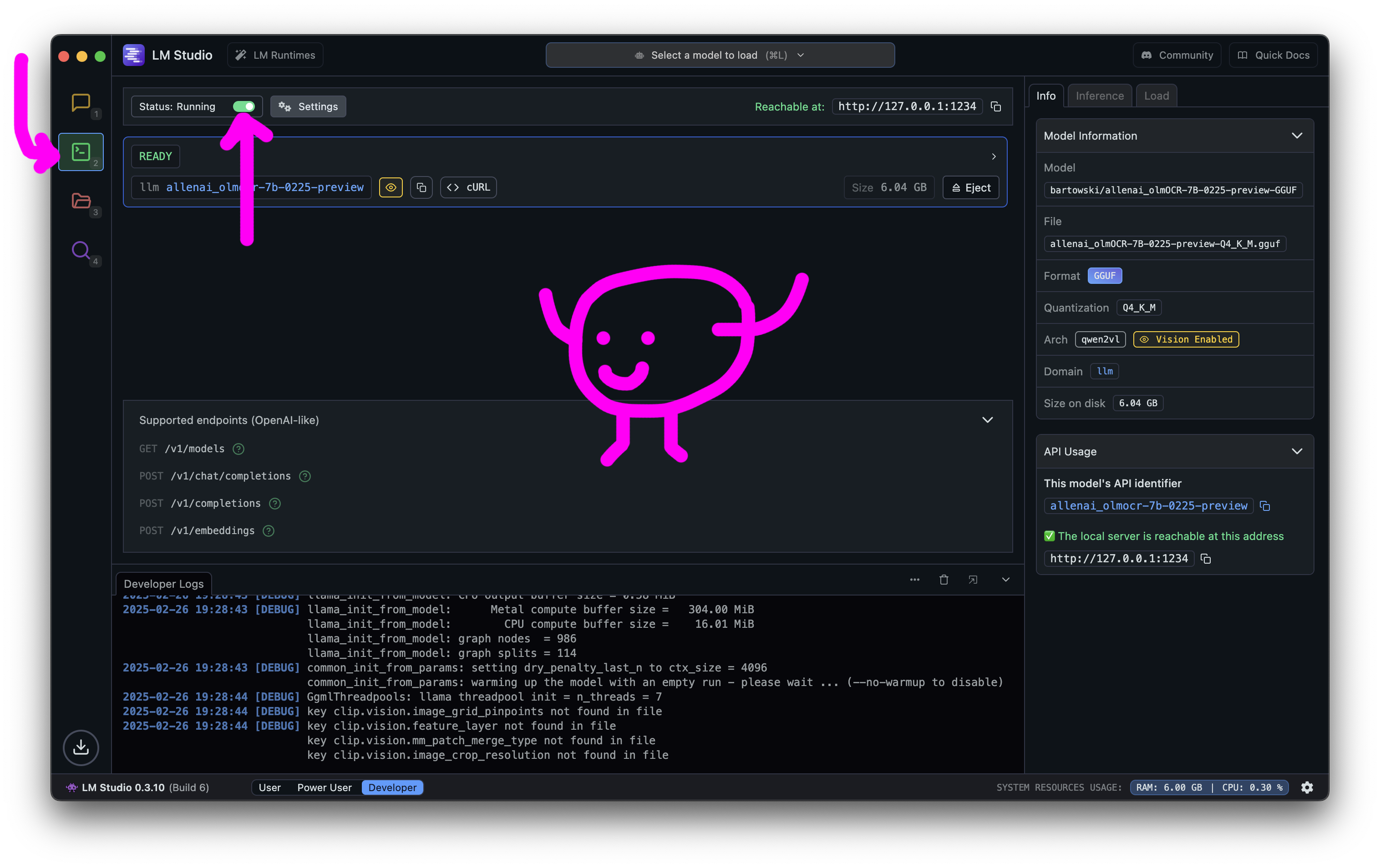
Using the model
Once the server is running it’s Python time! We’re going to install both the OpenAI library and the olmocr package. The OpenAI bindings allow us to talk to LM Studio, and olmocr ensures (kind of, somewhat, maybe) that we’re pre-processing correctly. I’m too lazy to think, and it was the easiest route.
First we’ll set up a connection to LM Studio. By default it runs at http://localhost:1234/v1 with the API key lm-studio. If you changed it in LM Studio – or are hosting your model elsewhere! – change it here.
from openai import OpenAI
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio", timeout=60)Our PDF in question is a one-page, slightly adulterated version of a sample from the original olmocr repo.
!(a sample pdf)[assets/00-demo.png]
Now we’re going to kidnap build_page_query from the olmocr package. It takes a PDF filename, a page, and a few extra parameters. It returns something that looks awfully like a normal OpenAI API call!
It includes the image of the PDF page base64-encoded as the image’s url. I’ve shortened it so we can actually see what’s going on.
from pprint import pprint
from olmocr.pipeline import build_page_query
query = await build_page_query("sample.pdf",
page=1,
target_longest_image_dim=1024,
target_anchor_text_len=6000)
query{'model': 'Qwen/Qwen2-VL-7B-Instruct',
'messages': [{'role': 'user',
'content': [{'type': 'text',
'text': 'Below is the image of one page of a document, as well as some raw textual content that was previously extracted for it. Just return the plain text representation of this document as if you were reading it naturally.\nDo not hallucinate.\nRAW_TEXT_START\nPage dimensions: 612.0x792.0\n[Image 0x0 to 612x792]\n\nRAW_TEXT_END'},
{'type': 'image_url',
'image_url': {'url': 'data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAxgAAAQACAIAAADtPWhLAAAACXBIWXMAAA5QAAAOUAEG8RVQAAAgAElEQVR42uzdeXxMZ+P//2uyT2SRTRJBFktoYieWUopqLaWlaC3FjZbWVm7aopZaWnvRBbUWtavSEMQeSxCakCAhicgiIrInss38/rg+9/nNdxJpSCzR1/MPjzPXuebMda5zMvN2luuotFqtAAAAwJMzoAsAAAAIUgAAAAQpAAAAghQAAABBCgAAAAQpAAAAghQAAABBCgAAgCAFAABAkAIAAABBCgAAgCAFAABAkAIAACBIAQAAEKQAAABAkAIAACBIAQAAEKQAAAAIUgAAACBIAQAAEKQAAAAIUgAAAAQpAA...etc'}}]}],
'max_tokens': 3000,
'temperature': 0.8}Now we’ll send this request to our OCR engine, tweaking the model name. Tada, we get exactly the response we’re looking for: a nicely-done OCR’d document.
query['model'] = 'allenai_olmocr-7b-0225-preview'
response = client.chat.completions.create(**query)
print(response.choices[0].message.content)INFO:httpx:HTTP Request: POST http://localhost:1234/v1/chat/completions "HTTP/1.1 200 OK"{"primary_language":"en","is_rotation_valid":true,"rotation_correction":0,"is_table":false,"is_diagram":false,"natural_text":"Chapter 2\nMathematical Induction:\n“And so on . . .”\n\n2.1 Introduction\nThis chapter marks our first big step toward investigating mathematical proofs more thoroughly and learning to construct our own. It is also an introduction to the first significant proof technique we will see. As we describe below, this chapter is meant to be an appetizer; a first taste of what mathematical induction is and how to use it. A couple of chapters from now, we will be able to rigorously define induction and prove that this technique is mathematically valid. That’s right, we’ll actually prove how and why it works! For now, though, we’ll continue our investigation of some interesting mathematical puzzles, with these particular problems hand-picked by us for their use of inductive techniques.\n\n2.1.1 Objectives\nThe following short sections in this introduction will show you how this chapter fits into the scheme of the book. They will describe how our previous work will be helpful; they will motivate why we would care to investigate the topics that appear in this chapter, and they will tell you our goals and what you should keep in mind while reading along to achieve those goals. Right now, we will summarize the main objectives of this chapter for you via a series of statements. These describe the skills and knowledge you should have gained by the conclusion of this chapter. The following sections will reiterate these ideas in more detail, but this will provide you with a brief list for future reference.\n\nWhen you finish working through this chapter, return to this list and see if you understand all of these objectives. Do you see why we outlined them here as being important? Can you define all the terminology we use? Can you apply the techniques we describe?"}Did this take a while? Yes! But still, it worked.
Honestly, the original request should have a little extra stuff in it. But LM Studio seems to be broken for some sorts of vision language model queries at the moment? I put in an issue so hopefully it will be resolved. For now you’ll find your queries break on any PDFs that have a fair amount of existing text.
Cleaning it up
To make things more official we’re going to wrap it all up in a bastardized version of olmocr’s process_page. While we adhere to the convention of returning a PageResponse, I’ve deleted pretty much everything else. I’ve removed a lot of error handling.
import json
from pathlib import Path
from tqdm.notebook import trange
from pypdf import PdfReader
from olmocr.pipeline import build_page_query, build_dolma_document, PageResult
from olmocr.prompts import PageResponse
async def process_page(filename, page_num):
query = await build_page_query(filename,
page=1,
target_longest_image_dim=1024,
target_anchor_text_len=6000)
query['model'] = 'allenai_olmocr-7b-0225-preview'
response = client.chat.completions.create(**query)
model_obj = json.loads(response.choices[0].message.content)
page_response = PageResponse(**model_obj)
return PageResult(
filename,
page_num,
page_response,
input_tokens=response.usage.prompt_tokens,
output_tokens=response.usage.completion_tokens,
is_fallback=False,
)
filename = "sample.pdf"
reader = PdfReader(filename)
num_pages = reader.get_num_pages()
results = []
for page_num in trange(1, num_pages + 1):
result = await process_page(filename, page_num)
results.append(result)Let’s pull out the text itself across all the pages:
text = '\n'.join([result.response.natural_text for result in results])
print(text)Chapter 2
Mathematical Induction:
"And so on . . ."
2.1 Introduction
This chapter marks our first big step toward investigating mathematical proofs more thoroughly and learning to construct our own. It is also an introduction to the first significant proof technique we will see. As we describe below, this chapter is meant to be an appetizer; a first taste, of what mathematical induction is and how to use it. A couple of chapters from now, we will be able to rigorously define induction and prove that this technique is mathematically valid. That's right, we'll actually prove how and why it works! For now, though, we'll continue our investigation of some interesting mathematical puzzles, with these particular problems hand-picked by us for their use of inductive techniques.
2.1.1 Objectives
The following short sections in this introduction will show you how this chapter fits into the scheme of the book. They will describe how our previous work will be helpful; they will motivate why we would care to investigate the topics that appear in this chapter, and they will tell you our goals and what you should keep in mind while reading along to achieve those goals. Right now, we will summarize the main objectives of this chapter for you via a series of statements. These describe the skills and knowledge you should have gained by the conclusion of this chapter. The following sections will reiterate these ideas in more detail, but this will provide you with a brief list for future reference.
When you finish working through this chapter, return to this list and see if you understand all of these objectives. Do you see why we outlined them here as being important? Can you define all the terminology we use? Can you apply the techniques we describe?Beautiful!
Build the dolma results
I don’t know what Dolma is, but AI2 loves it. As a bonus we can reproduce the olmocr dolma representations, which are a series of jsonl files.
output_folder = Path("workspace/results")
output_folder.mkdir(exist_ok=True, parents=True)
doc = build_dolma_document(filename, results)
dolma_path = output_folder.joinpath(filename).with_suffix(".results.jsonl")
dolma_path.write_text(json.dumps(doc) + "\n")We’ll use the CLI version of dolmaviewer because it’s easier than writing our own code.
!python -m olmocr.viewer.dolmaviewer workspace/results/*.jsonlProcessing documents: 100%|███████████████████████| 2/2 [00:00<00:00, 4.69it/s]
Output HTML-viewable pages to directory: dolma_previewsAnd now we can look at the output.
!open dolma_previews/sample_pdf.html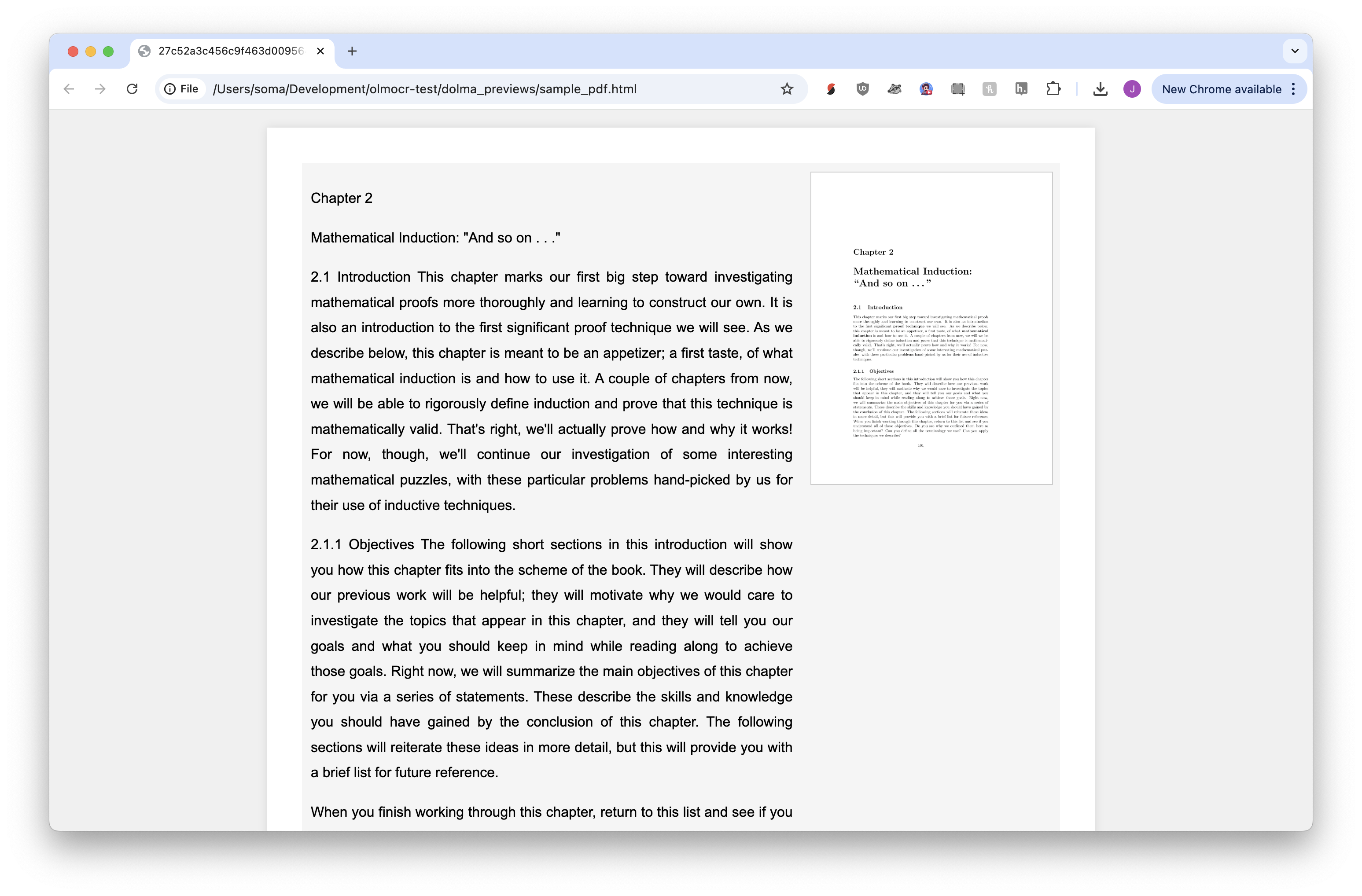
Magic.