Convert web pages to CSVs with pandas¶
1. What are your rows?¶
First you'll need to look at your web page and figure out visual part of the page becomes the rows of your dataset. Each row will probably be a person, a story, a product, or something else.
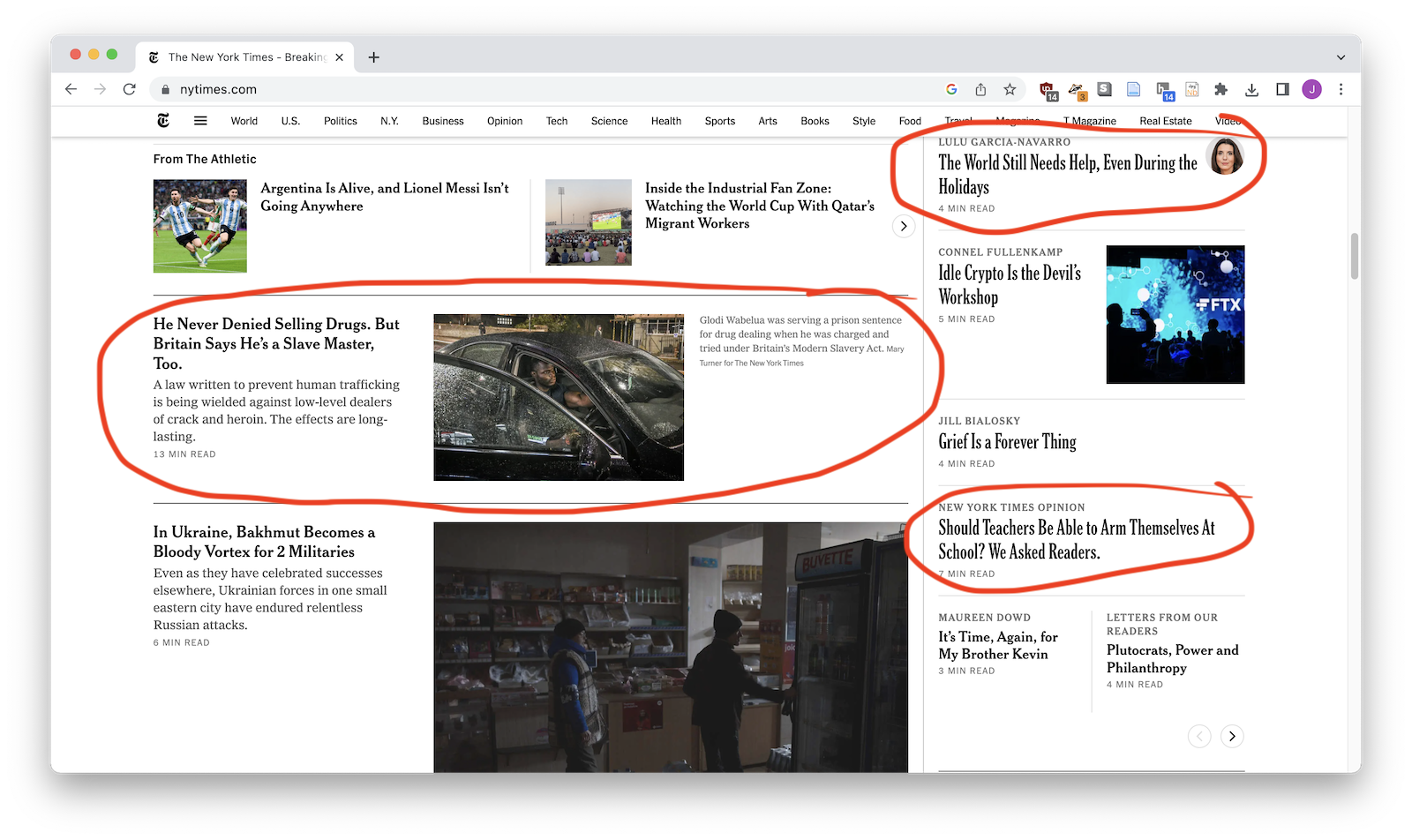
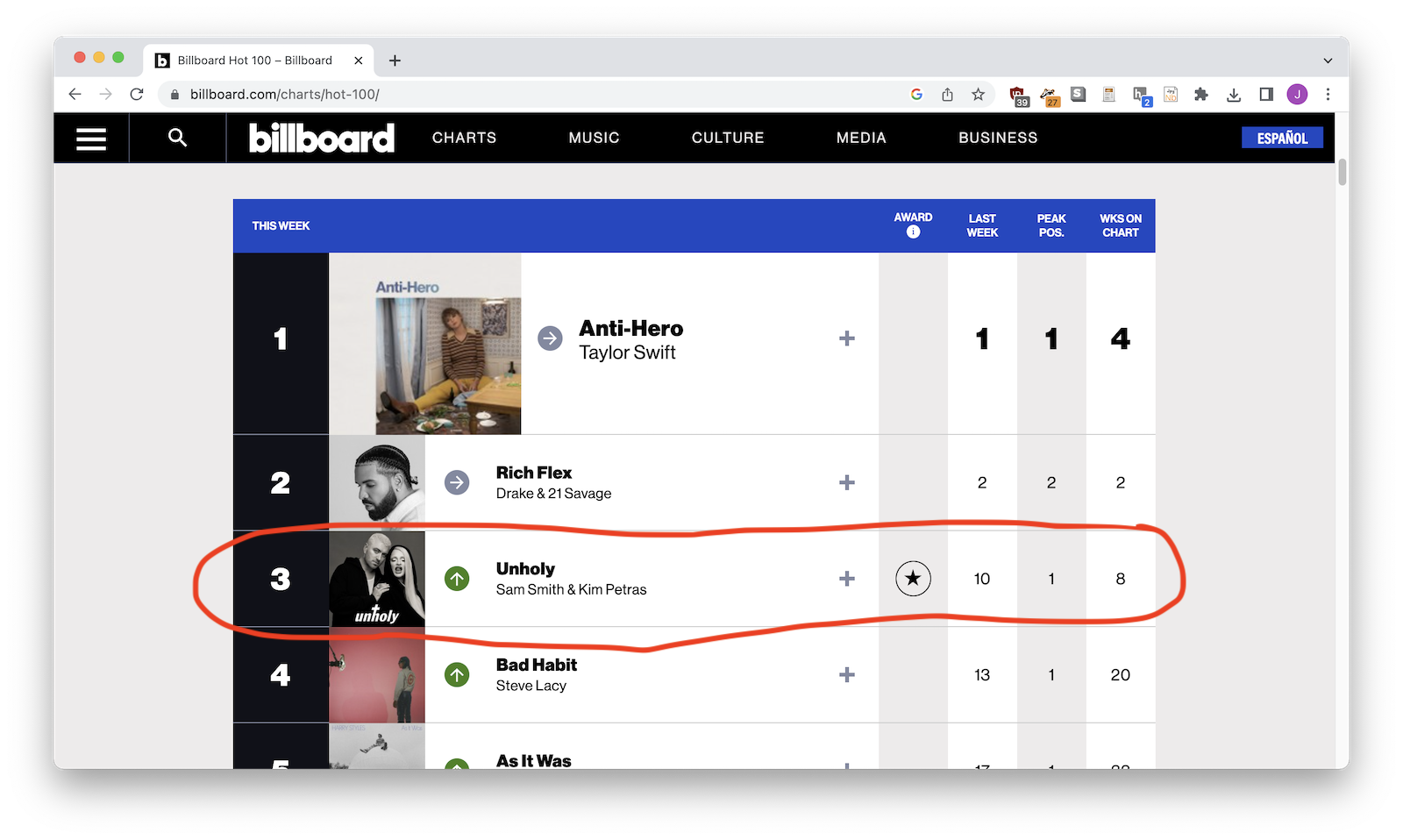
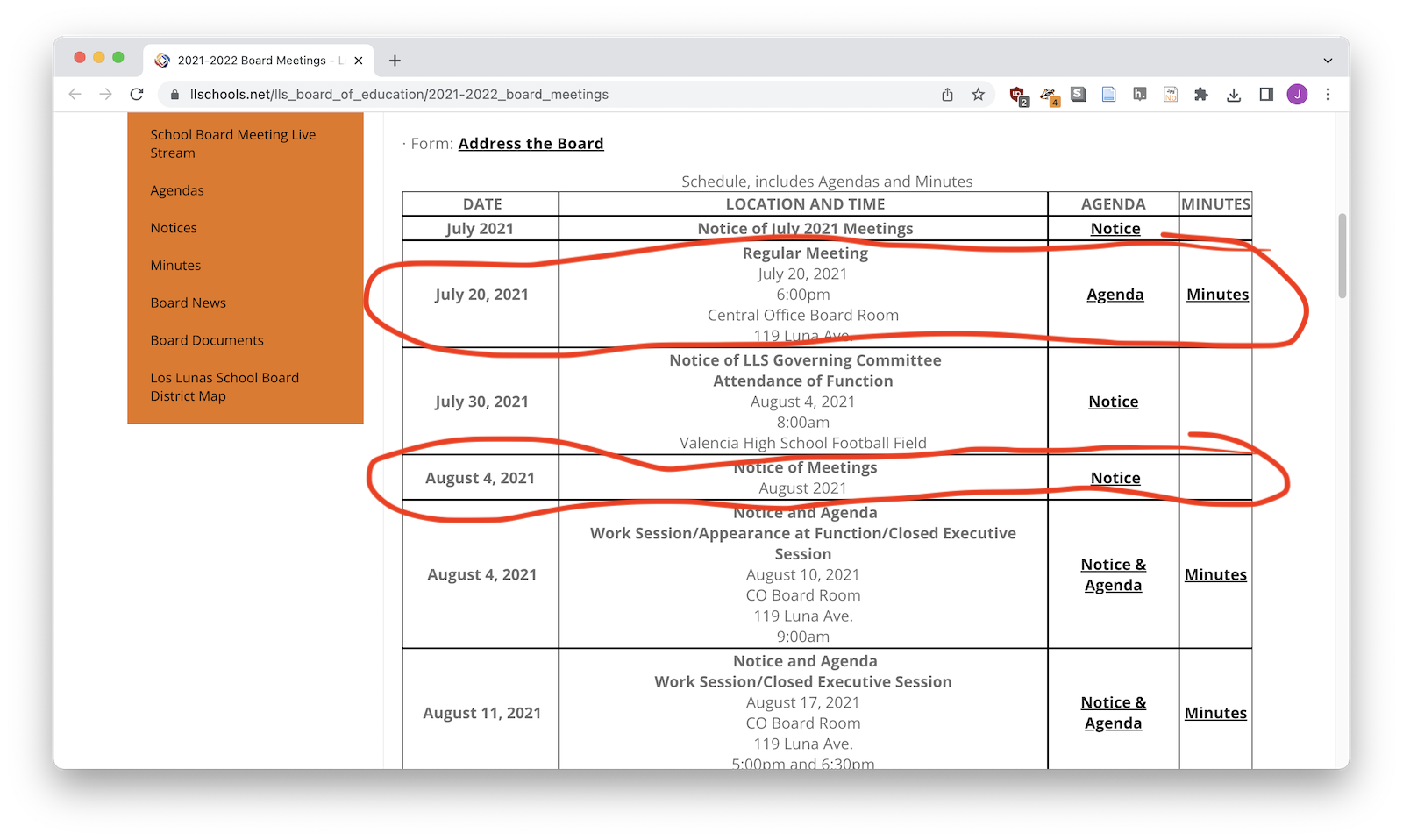
2. Find the HTML wrappers¶
Second you'll try to the HTML element that wraps each item. It might be a <div>, it might be a <tr>. You'll nee to use the web inspector to find it.
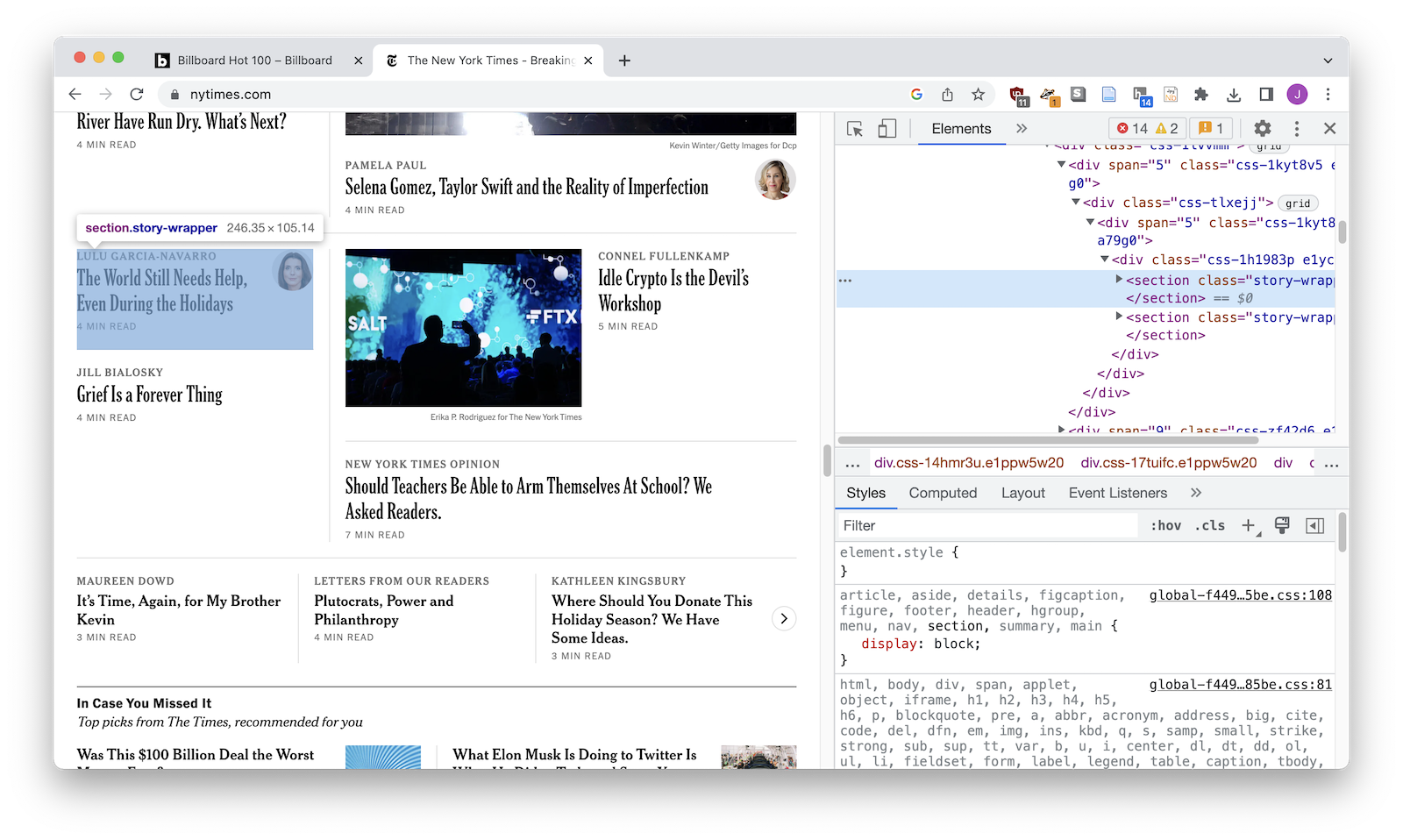
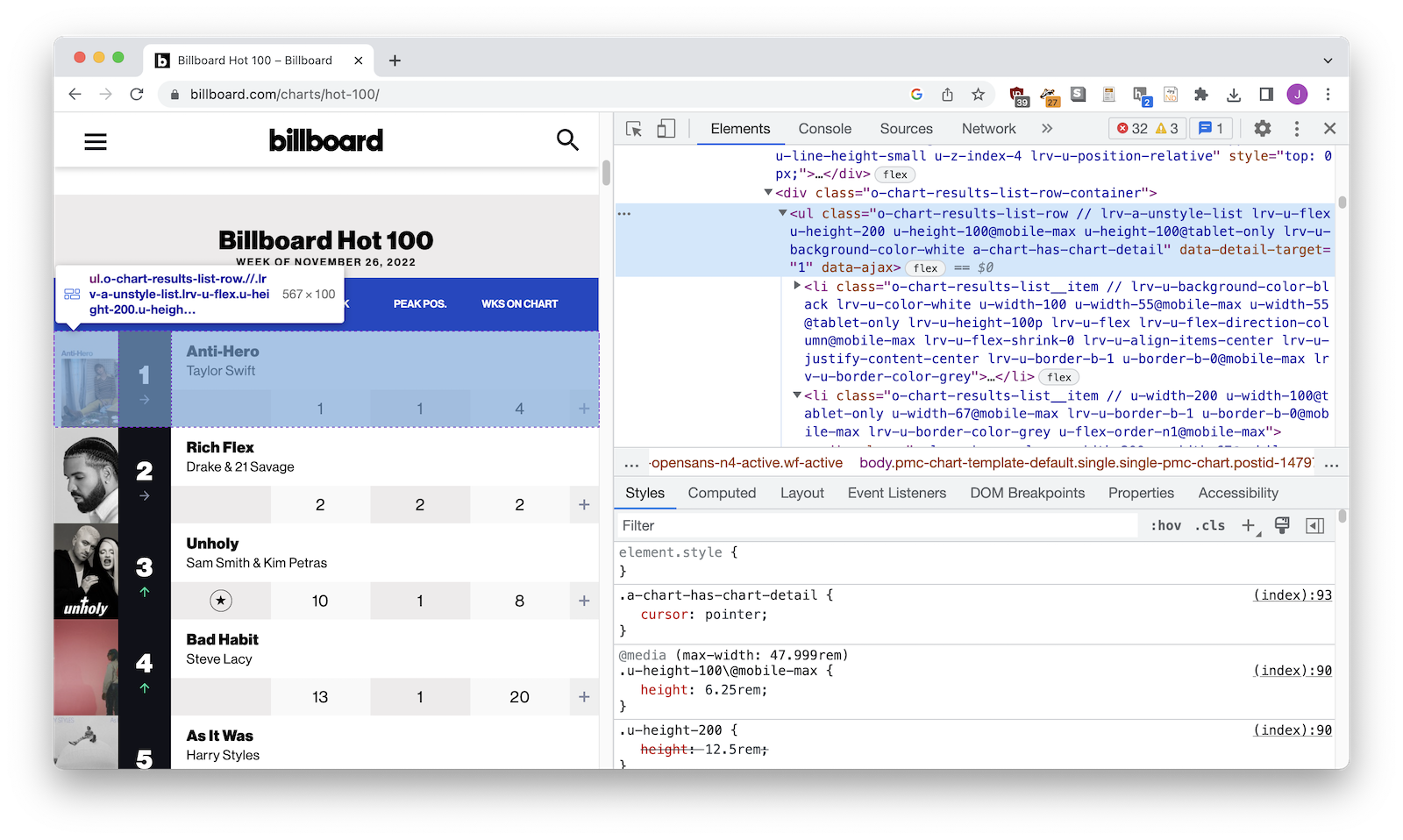
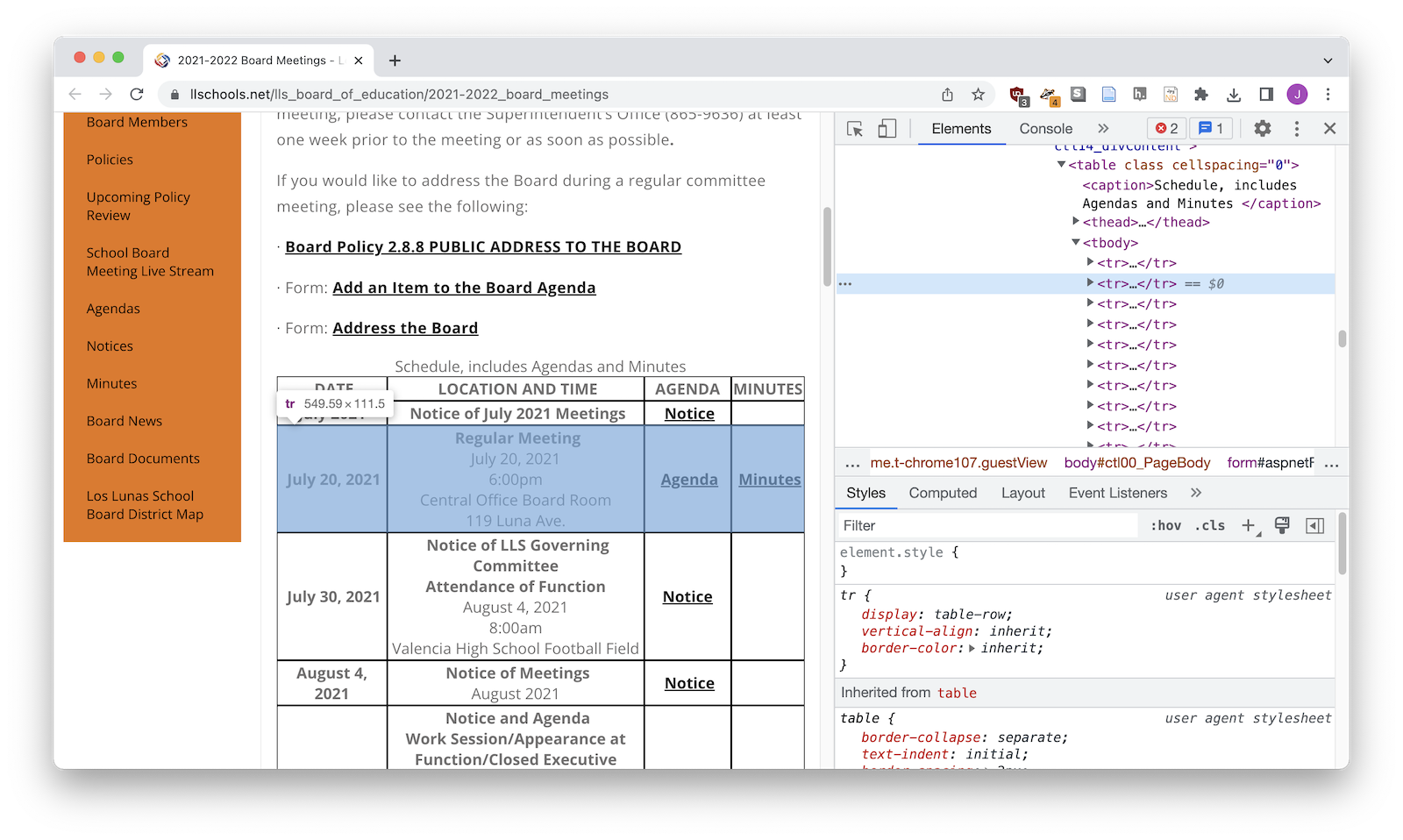
3. Find a selector for your HTML wrappers¶
Now you'll need to figure out how to talk to Python about those HTML wrappers. If you're lucky you'll be looking for <div class="story-wrapper"> but sometimes it's a little more complicated!
I personally like to use CSS selectors because I find it easiest to figure out how to pick your way down into the content you're looking for. For example, the CSS selectors for our examples are....
- New York Times:
.story-wrapper - Billboard:
.o-chart-results-list-row - Schoolboard minutes:
tr
CSS selector inspiration for rows¶
| CSS selector example | What it means |
|---|---|
div |
Select all <div> elements |
div.story-wrapper |
Select all <div> elements with the class story-wrapper |
.story-wrapper |
Select all elements with the class story-wrapper |
#content .story-wrapper |
Select all elements with the class story-wrapper that are inside of something with the id of content |
div.story-wrapper > p |
Select all <p> elements that are inside of a <div> with the class story-wrapper |
table.minutes-table tbody tr |
Select all <tr> elements that are inside of a <tbody> that is inside of a <table> with the class minutes-table |
4. Write your loop¶
Let's see if we did this right! Now you'll write a loop to check and make sure your wrapper is correct.
In this example I'm using BeautifulSoup for everything, but it'll work fine with Selenium or Playwright as well
Does it print out what you were hoping? If it prints out extra content, that's usually okay, we can clean it up later. If it prints out less content than you were hoping, you'll need to tweak your selector.
5. Find your columns¶
Now make note of everything that will end up as a column.
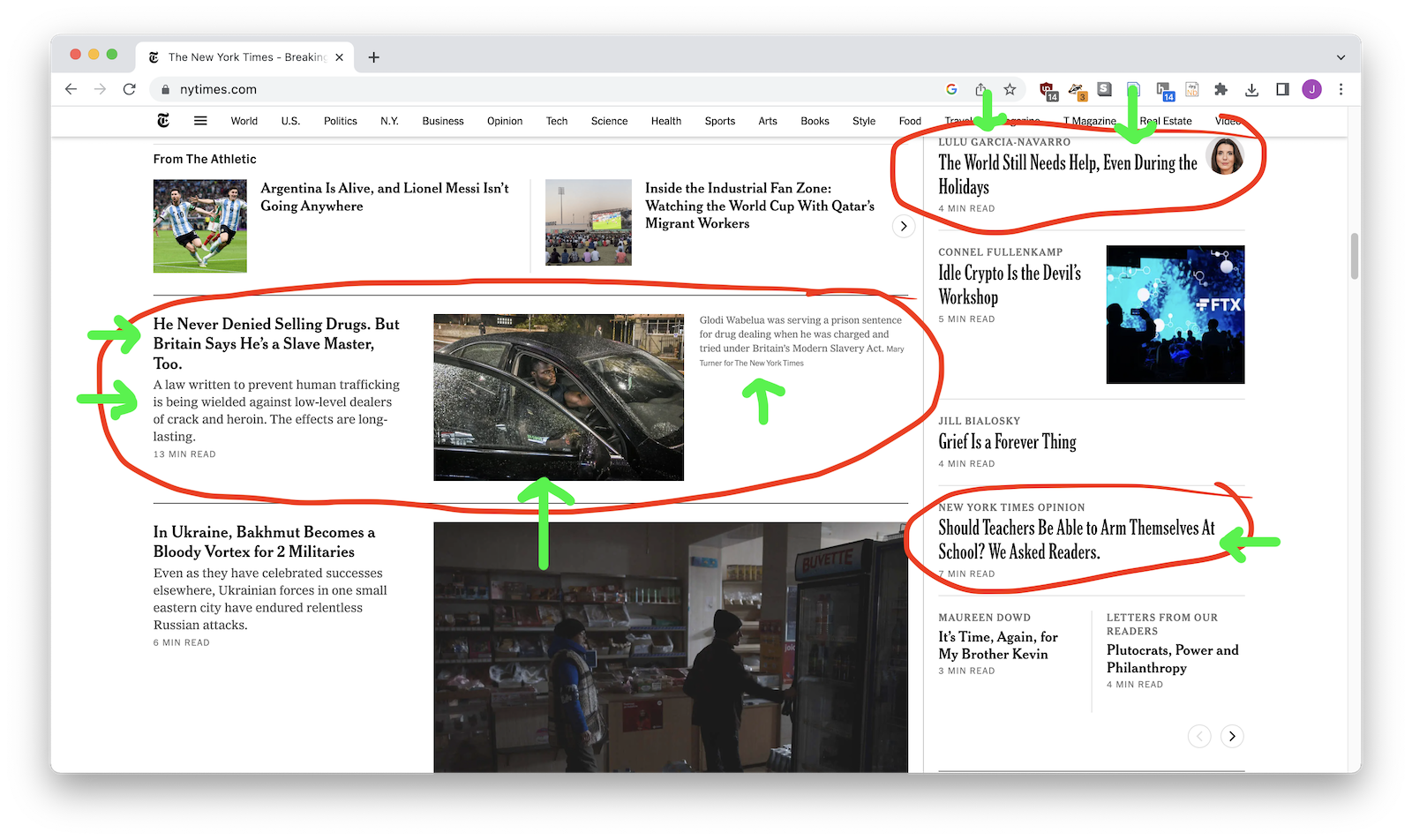
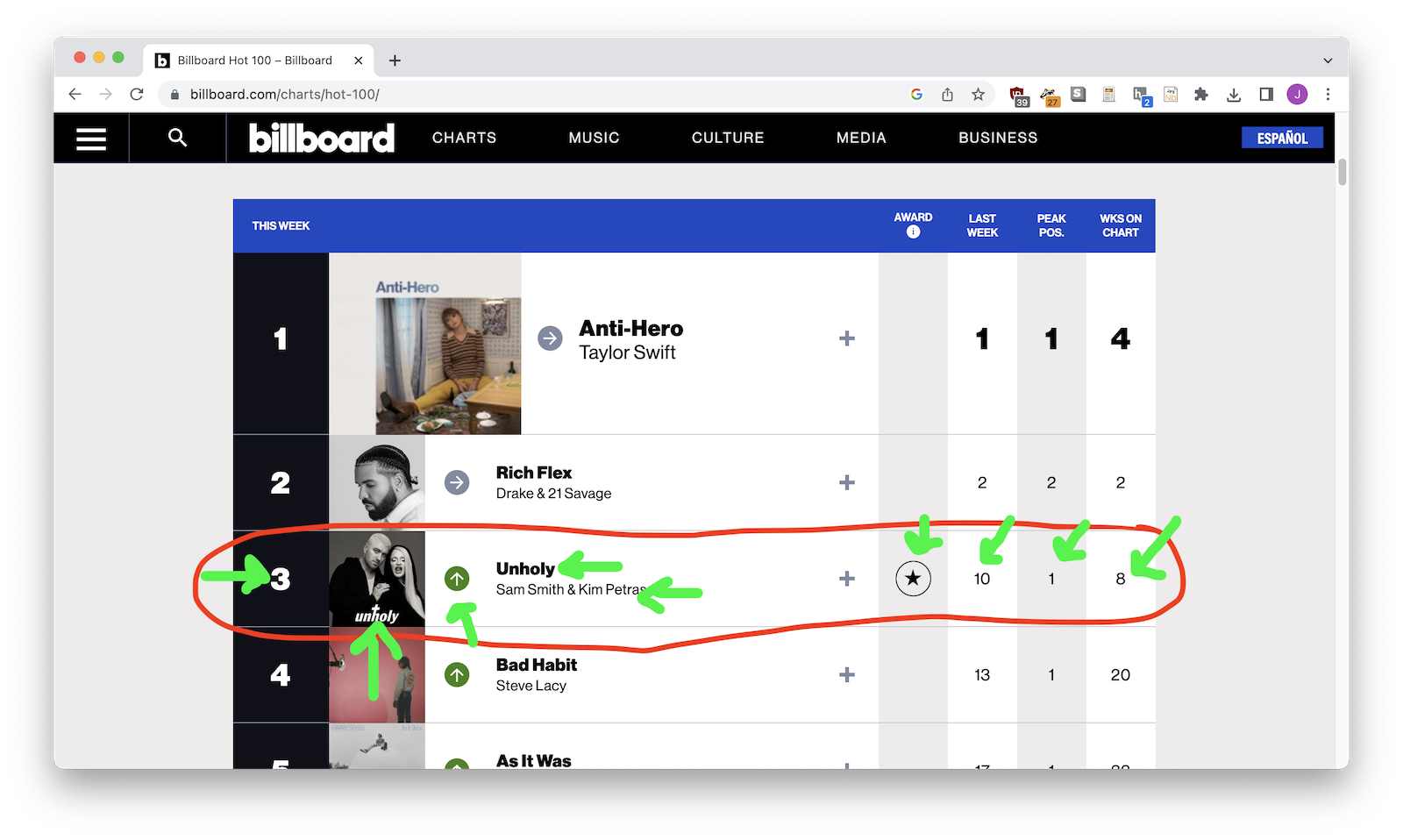
6. Select your columns¶
In the same way you needed to figure out the right selectors for the rows, yo'ull need to do the same for the columns. I recommend doing them one by one, testing after each, going through a process like this:
# This won't work for the NYT, it's just an example!
stories = doc.select('div.story-wrapper')
for story in stories:
print("----")
# Get the headline, comment out when it's working
# title = story.select_one('h2.story-heading').text
# print(title)
# Get the story link, comment out when it's working
link_url = story.select_one('a[href]')['href']
print(link_url)
If not every row is going to have all of the columns, you can use try and except to say "try to do this, but if it doesn't work, just keep going!"
# This won't work for the NYT, it's just an example!
stories = doc.select('div.story-wrapper')
for story in stories:
print("----")
# Get the headline, comment out when it's working
# title = story.select_one('h2.story-heading').text
# print(title)
# Get the story link, comment out when it's working
try:
link_url = story.select_one('a[href]')['href']
print(link_url)
except:
print("No link for this story")
CSS selector inspiration for columns¶
| CSS selector example | What it means |
|---|---|
h3 |
Select all <h3> elements |
h3.story-title |
Select all <h3> elements with the class story-title |
a[href] |
Select all <a> elements that have an href attribute |
a[href$="pdf"] |
Select all <a> elements that have an href attribute that end with pdf |
a[href*="2002"] |
Select all <a> elements that have an href attribute that include the text 2002 |
td:nth-child(3) |
Select the third <td> element in a row |
7. Create a list of dictionaries¶
We started by printing everything out...
# This won't work for the NYT, it's just an example!
stories = doc.select('div.story-wrapper')
for story in stories:
print("----")
# title = story.select_one('h2.story-heading').text
# print(title)
link_url = story.select_one('a[href]')['href']
print(link_url)
...but now instead of printing them out, we're going to save them into brand-new dictionaries.
# Start with zero rows
rows = []
# This won't work for the NYT, it's just an example!
stories = doc.select('div.story-wrapper')
for story in stories:
print("----")
# We start saying each row has no data
row = {}
row['title'] = story.select_one('h2.story-heading').text
try:
row['link_url'] = story.select_one('a[href]')['href']
except:
pass
# Print it out just to help with debugging
print(row)
# Add our current row to our list of rows
rows.append(row)
8. Convert into a DataFrame¶
The best reason to use pandas for this is data cleaning! We probably pulled in some stuff we didn't need, or weren't able to separate all of our columns earlier on. Now that we can push our list of dictionaries into pandas, life gets a lot easier.
import pandas as pd
# pandas doesn't care if the keys are different,
# it will just fill in the blanks with NaN
df = pd.DataFrame(rows)
df.head()