Pretending to be a browser with requests and BeautifulSoup¶
Some web servers are insistent that no one scrape them. There are a lot of levels you can use to get around these sorts of restrictions. While using a browser automation tool like Selenium or Playwright is the most powerful, it's also more complicated and slower. If you're just getting started with web scraping or have a lot lot lot of pages to scrape, you might want to start with something simpler first.
Faking your User-Agent¶
The easiest way to pretend to be a browser is to change your User-Agent. A User-Agent is a string that tells the web server what kind of browser you're using.
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac macOS 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'}
requests.get('https://www.example.com', headers=headers)
Spoofing a real web browser request¶
When you visit a web site, a lot more information beyond just your User-Agent is sent to the web server. Instead of building up the pieces from scratch, you can instead copy a request from your browser and send it to the web server using requests. Sometimes this gives enough information that you can just use requests and BeautifulSoup instead of a web automation tool.
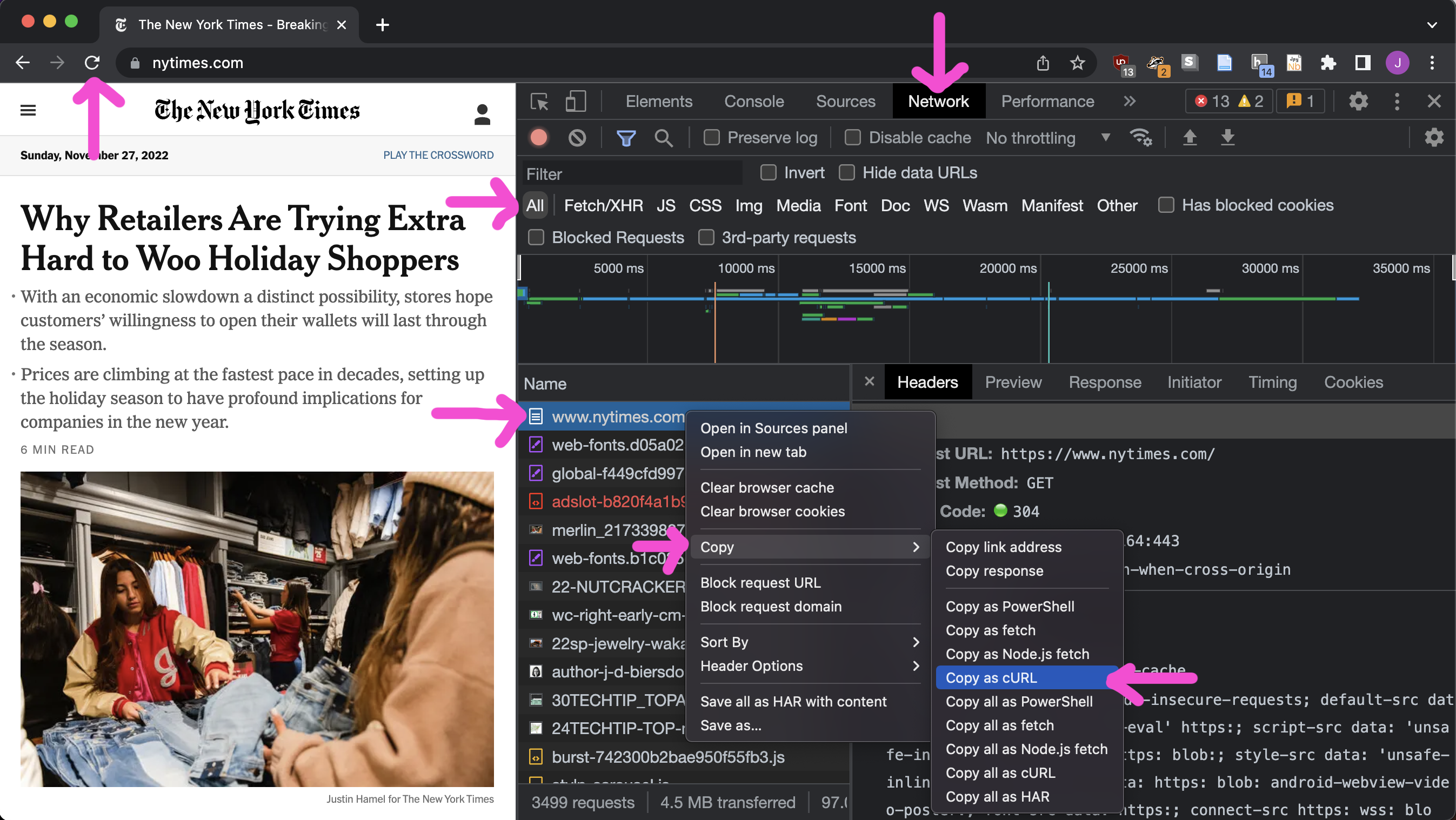
There are a few ways to do this. My favorite is to use the Copy as cURL option from the Chrome developer tools.
- Open up the developer tools
View > Developer > Developer Toolsor⌘⌥I - Click on the Network tab
- Visit the web page you want to scrape
- Right click on the request you want to copy – it's probably the one at the top of the list – and select Copy > Copy as cURL (or cURL (bash) if you're on Windows).
It will give you something awful that is not Python code – it's curl code, for the command line – so you'll want to visit https://curlconverter.com/ to convert it to Python code. The result will still be long and awful, but you'll probably be able to understand a little more of it:
import requests
cookies = {
'nyt-a': '02M776PT3GdGh6vDY0h',
'purr-cache': '<K0<rC_<G',
'NYT-T': 'ok',
'nyt-auth-method': 'username',
'b2b_cig_opt': '%7B%22isrpUser%22%7D',
'nyt-gdpr': '0',
'nyt-geo': 'US',
'nyt-cmots': '',
'datadome': '7WcR9I_RUGozflOibxruPWQ5ftYU7YvwVb1oUDgMUc95fL0qNbqHLGbBQAs4zzyVaUzKv22PnEkMMoKZ5pFXlYSzmA-G2xPd6owLFhf34wg',
'nyt-m': '-46a4-8b1a-9c297914e621&prt=i.0&ft=i.0&fv=i.0&v=i.0&pr=l.4.0.0.0.0&ier=i.0&iru=i.1&t=i.2&imv=i.0&igf=i.0&ira=i.0&igu=i.1&e=i.1669903200&iir=i.0',
'nyt-b3-traceid': 'dbc374352dfc4bd86067635aa1654',
'nyt-purr': 'cfhhhhckfh',
'SIDNY': 'CBMSKQJ-I--8luzWAMgGFADsN',
}
headers = {
'authority': 'www.nytimes.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-US,en;q=0.9,ru;q=0.8',
'cache-control': 'max-age=0',
'dnt': '1',
'if-modified-since': 'Mon, 28 Nov 2022 00:06:21 GMT',
'sec-ch-ua': '"Google Chrome";v="107", "Chromium";v="107", "Not=A?Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'sec-gpc': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac macOS 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
}
response = requests.get('https://www.nytimes.com/', cookies=cookies, headers=headers)
Cut and paste that into your Python code and you might be able to scrape the page!